AI red teaming platform
Automated campaigns test deployed AI systems across chatbots, copilots, RAG apps, coding agents, internal agents, and model endpoints.
Loading page...
AI Red Teaming Platform
General Analysis is an automated AI red teaming platform for LLM applications, RAG systems, MCP servers, coding agents, and production AI agents. Test prompt injection, tool misuse, data leakage, unsafe autonomy, and multi-step agent attacks before they reach users.
Finance support regression · v14 against guardrail candidate
finance-agent · guardrail candidate v14
Run continuous adversarial testing across LLM apps, RAG systems, MCP servers, coding agents, and production AI agents.
Find prompt injection, indirect injection, tool misuse, privilege escalation, memory abuse, and data exposure at the system boundary.
Turn attacks into reproducible traces, OWASP-mapped findings, remediation tasks, and release regression tests.
Built for adversaries
# Launch a red-team campaign with one command: # $ ga redteam launch -f campaign.yaml target: finance-agent algorithm: tap behaviors: - LLM01_prompt_injection - LLM02_data_disclosure - LLM06_excessive_agency - LLM07_sysprompt_leak config: runs: 425 workers: 4 depth: 4 export: siem,owasp
AI security platform coverage
Buyers searching for AI security platforms, AI TRiSM tools, LLM security testing, prompt injection security, and agentic AI security are usually asking for the same evidence. They need to know which AI systems exist, what those systems can reach, how they can be attacked, and whether fixes were verified.
Automated campaigns test deployed AI systems across chatbots, copilots, RAG apps, coding agents, internal agents, and model endpoints.
Coverage includes direct prompts, indirect instructions in documents and webpages, tool output poisoning, hidden context leakage, and jailbreak variants.
Campaigns exercise tools, permissions, memory, browser actions, MCP servers, approval gates, and multi-step business workflows.
Tests observe whether one tool, server, data source, or retrieved artifact can steer another privileged action across the agent graph.
Findings are mapped to security frameworks, asset owners, severity, affected systems, remediation steps, and policy changes.
Confirmed failures become regression tests and can feed runtime controls through guardrails, approval policies, and detection rules.
What gets tested
The platform tests the deployed AI system across the base model, prompts, tools, memory, retrieval, identity, and business logic so findings match the failures attackers would actually exploit.
Tests whether agents can be steered into unsafe tool calls, privilege escalation, data access outside policy, or multi-step workflows that bypass approval gates.
Runs direct, indirect, multi-turn, and retrieval-borne attacks against prompts, memories, documents, and connected knowledge bases.
Looks for sensitive prompt leakage, cross-tenant disclosure, unsafe citations, hidden context exposure, and exfiltration through connected tools.
Replays confirmed exploits against new model versions, prompt changes, tool updates, and policy changes before they reach production.
Ingest agents, prompts, tools, permissions, retrieval sources, policies, and business-critical actions so campaigns target the real attack surface.
Use automated attack strategies such as TAP, PAIR, Crescendo, encoding variants, and multi-turn social engineering to search for exploitable behavior.
Cluster duplicate attempts, assign severity, attach traces, and separate harmless policy friction from issues that create operational risk.
Turn each confirmed exploit into a regression test that runs against future deployments and feeds runtime controls when a guardrail is needed.
Guides and playbooks
Automated AI red teaming sits inside a broader AI security program. These guides connect the product page to the searches buyers use for AI security platforms, AI red teaming tools, guardrails, MCP security, and automated penetration testing.

Buyer guide
16 min readA practical 2026 buyer guide to AI security platforms across AI red teaming, agentic AI security, prompt injection protection, runtime controls, AI posture management, model supply chain security, and AI TRiSM.
Comparison
18 min readA practical 2026 comparison of AI red teaming and adversarial testing tools across automated red teaming, LLM security testing, prompt injection coverage, agentic AI testing, multi-step tool-chain attacks, framework support, and enterprise readiness.

Primer
18 min readAI red teaming is adversarial testing of AI systems to find exploitable vulnerabilities before attackers do. Learn how it works, key techniques, real exploit examples, and how to implement it.
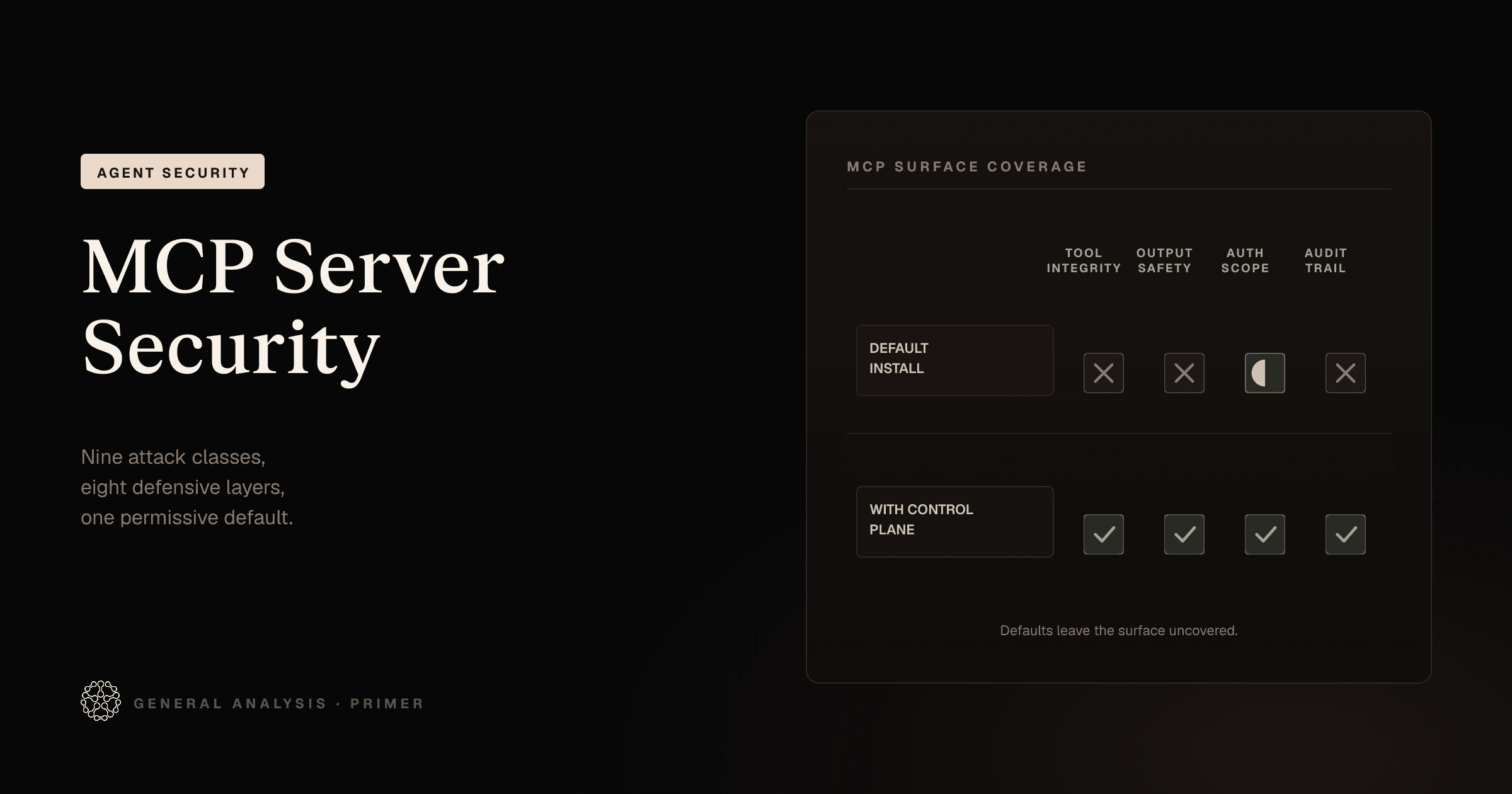
PRIMER
16 min readThe Model Context Protocol expanded what AI agents can reach, and expanded the attack surface across at least nine distinct vectors. A primary-source threat model for MCP servers, with concrete controls, real CVEs, and the GA Supabase exploit walked end to end.
PLAYBOOK
14 min readAn analytical guide to the AI guardrails landscape: the architecture behind runtime safety, the ten tools that matter, what adversarial benchmarks actually show, and the decisions that determine whether guardrails hold under pressure.

PLAYBOOK
18 min readA practical 2026 buyer guide to automated penetration testing platforms, autonomous pentesting, automated security validation, CTEM, DAST, BAS, and AI security testing.