RESEARCH
Case Study: Light-Weight Policy Moderators for Indeed Job Postings
8 min read
Loading blog content...
Loading page...
Loading blog content...

Our policy moderation models achieve human performance for job postings at <1% of today’s per-review cost of human moderation. Each policy employs a dedicated, compact model. Our model (F1 0.840) outperforms GPT-4o (F1 0.623), o4-mini (F1 0.837), and o3 (F1 0.835) while also operating faster and costing approximately 87% less.
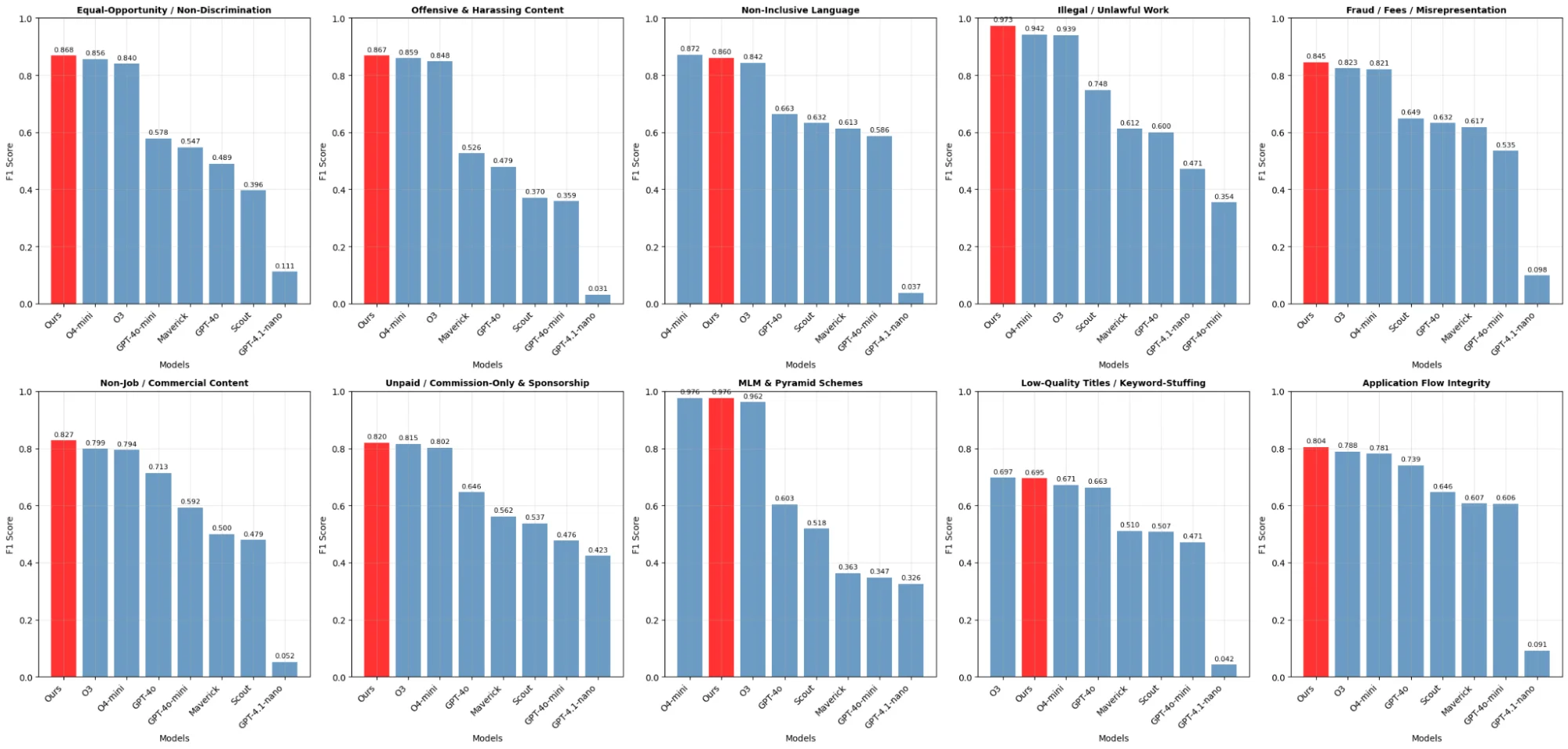
Figure 1: Model performance over harmful categories, measured in F1 score.
In this study we train high-performing, policy-specific moderation models using the Indeed dataset on Kaggle, applying an adversarial approach to evaluations. (Note that the public Indeed dataset mainly contains compliant postings, so we supplement it with synthetic data as detailed in the Data section.)
We moderate job advertisements according to 10 specific policies, grouped into two high-level classes: legal and internal. Each policy represents a clearly defined rule published on Indeed’s public Employer Help Centre, Partner Docs or Legal pages. Policies listed below are extracted directly from Indeed web resources.
| Policy label | Class | One-sentence scope |
|---|---|---|
| Equal-Opportunity / Non-Discrimination | legal | Job postings must not indicate preferences, limitations, or exclusions based on legally protected characteristics such as race, gender, age (40+), disability or religion. |
| Illegal / Unlawful Work | legal | Listings cannot solicit or facilitate employment involving activities that violate local laws, including drug trafficking, unauthorized gambling, or computer hacking. |
| Offensive & Harassing Content | internal | Titles, descriptions, and application instructions must remain professional, avoiding vulgarity, hateful speech, or explicit sexual language. |
| Non-Inclusive Language | internal | Indirect or implicit bias terms – such as age-related descriptors (“young”), gender-specific titles (“handyman”), and lifestyle requirements (“non-smoker”) – are prohibited, except when justified by a legitimate, occupational necessity. |
| Fraud / Fees / Misrepresentation | internal | Ads must accurately identify the hiring employer, clearly describe the job duties, and never require candidates to make payments or buy products as a prerequisite for consideration. |
| Non-Job / Commercial Content | internal | Indeed forbids postings unrelated to genuine employment, such as franchise opportunities, paid training courses, or promotional events requiring ticket purchases. |
| Unpaid / Commission-Only & Sponsorship | internal | Jobs offering solely unpaid or 100% commission-based compensation must clearly disclose these conditions and typically require paid sponsorship for visibility in organic results. |
| MLM & Pyramid Schemes | internal | Multi-level marketing (MLM), pyramid schemes, or any role that primarily generates earnings through recruiting additional members is disallowed. |
| Low-Quality Titles / Keyword-Stuffing | internal | Job titles must clearly and succinctly state the position; listings containing clickbait, excessive emoji usage, or keyword repetition will be demoted or removed. |
| Application Flow Integrity | internal | Candidates must apply through Indeed or an approved applicant tracking system (ATS). Ads must not redirect applicants to unverified channels such as personal emails, WhatsApp, or external Google forms. |
We utilize the publicly available “Indeed Job Posting Dataset”, compiled by PromptCloud and DataStock and hosted on Kaggle. The full corpus includes 325,946 job advertisements collected from Indeed.com between August 1 and October 31, 2019. All content appears under a CC-0 (public domain) license, allowing unrestricted redistribution and annotation. For this study, we randomly select a subset of 10,000 data points.
The dataset is heavily skewed toward compliant postings, which is a common pattern in fraud detection and non-compliant data. Violations of even the most common rule occur in <8% of records, while several policies appear in ≤1% of cases and one shows no positives at all.
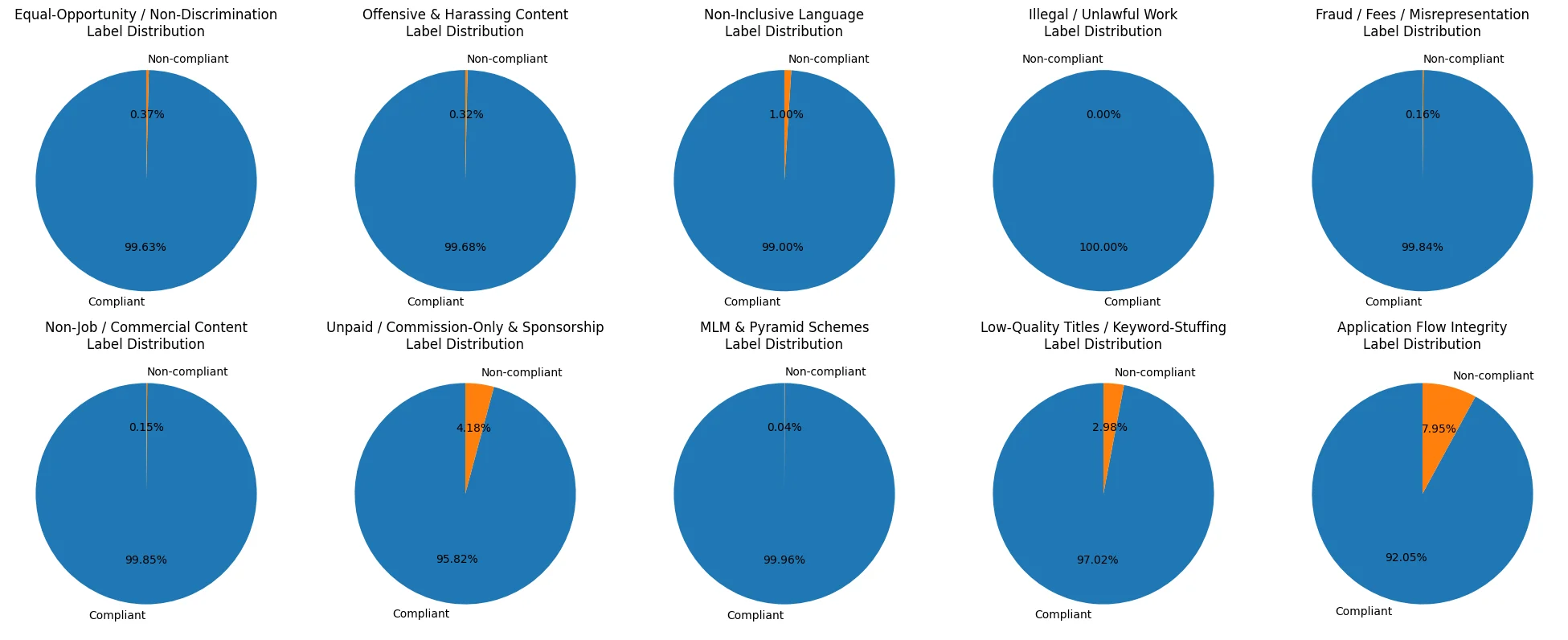
Figure 2: Class frequency of the Indeed Kaggle dataset.
To address the imbalance, we created a synthetic violation dataset containing 2,000 posts. We generated each sample using few-shot prompting with OpenAI's o4 (high reasoning) model. Each prompt comprised one randomly selected compliant ad and two curated examples violating the target rule. From these prompts, o4 produced a new, non-compliant post reflecting the tone, length, and domain cues of the provided examples.
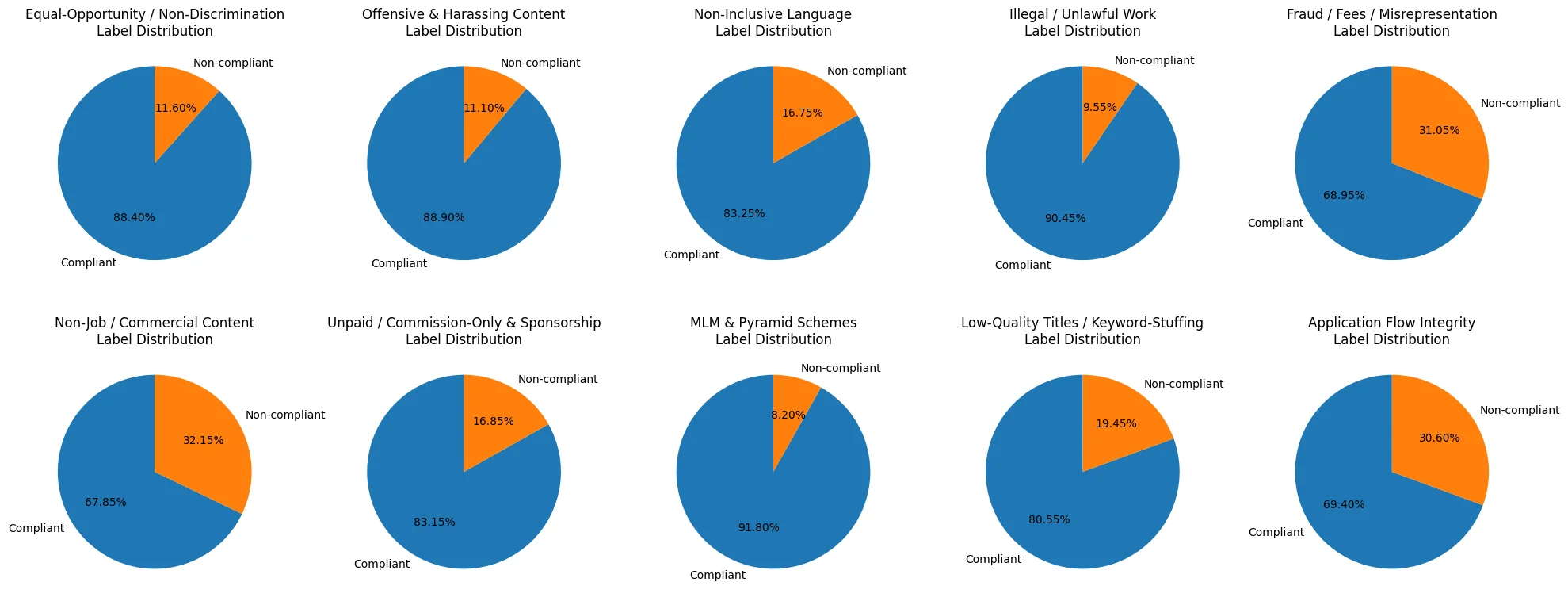
Figure 3: Class frequency after augmenting with synthetic data.
We automatically generate policy labels through structured debates between our strongest available reasoning models. Each debate involves two models: one arguing for compliance of the datapoint and the other arguing against it. After two rounds of argument, a judge evaluates both sides and selects the most persuasive argument. To improve reliability, we repeat this process three times using a self-consistency pipeline and assign the final label based on majority voting.
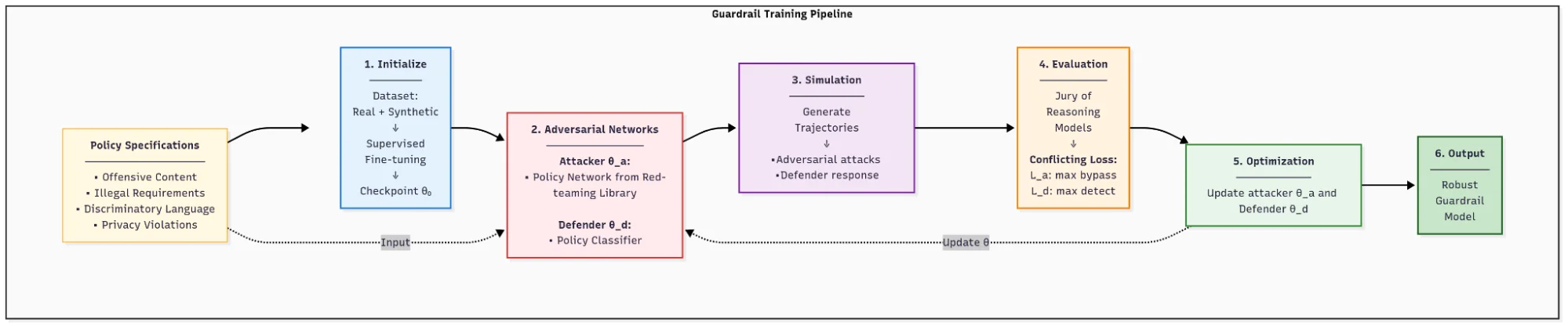
Figure 4: Workflow of our Guardrail Training Pipeline.
Our moderation system leverages reinforcement learning, domain-specific fine-tuning, and various data science tricks.
We begin with running supervised fine-tuning for each policy classifier on a comprehensive dataset combining real and synthetic examples. This initial step provides the model a robust representation of known compliant and non-compliant cases.
After establishing the base model, we deploy a proprietary red-teaming agent designed specifically to uncover potential vulnerabilities. This attacker, a learned policy network, crafts adversarial examples intended to bypass the moderation classifiers. It utilizes an extensive suite of known attack vectors, both from external research and developed internally by our red-teaming experts.
During training, the attacker and defender evolve jointly under conflicting objectives: the attacker aims to generate challenging examples capable of circumventing moderation rules, while the defender attempts to detect these adversarial attempts accurately. A jury of reasoning models assess the defender's performance on these difficult samples.
Through an iterative process, this adversarial setup systematically identifies and corrects weaknesses within the moderation system. Specific training methodologies are proprietary.
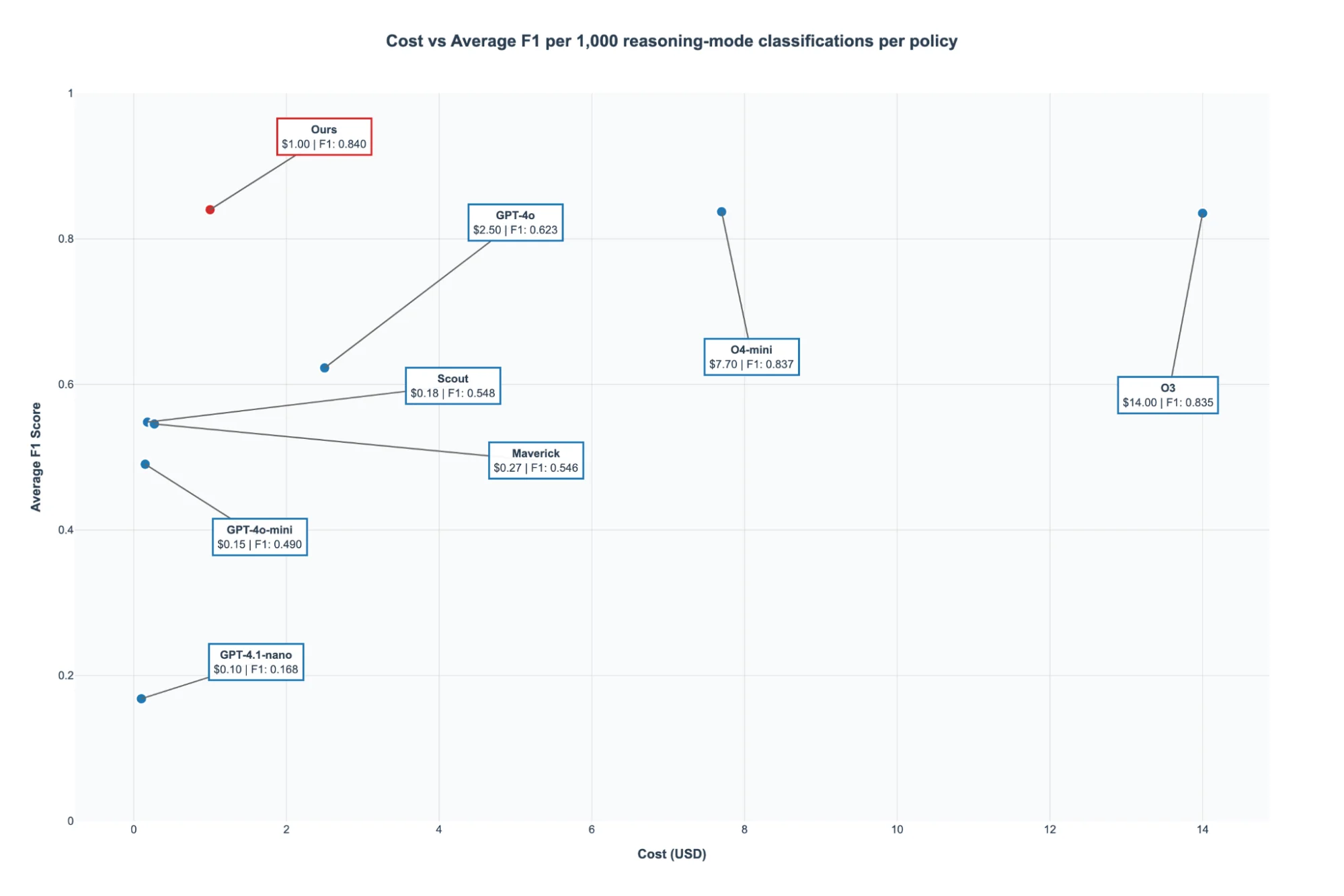
Figure 5: Cost-performance coordinates of different moderation methods.
Figure 5 summarizes the trade-off between cost and performance. While reasoning-based models deliver strong F1 scores, their inference costs are several times higher than non-reasoning alternatives. Our approach achieves competitive performance comparable to reasoning models but at significantly lower cost. This cost reduction comes from leveraging domain-specific fine-tuning on a smaller model, and our library of proprietary red-teaming algorithms.
Estimated savings and performance improvements per 100,000 moderation requests:
Have domain-specific rules beyond job postings? We build compact, high-accuracy moderators for any policy set (legal, safety, quality, brand, workflow integrity) and integrate them into your stack. If you want us to enforce custom policies on anything you care about, reach out at info@generalanalysis.com.